



Quick Generate

Create Your Own AI Model
Model Description by Creator
Warning:
This model was really just a trial run for me to learn about training LoRAs, and as such I make no guarantees or claims to it being high quality, without errors, or even any good. I find that it produces usable and relatively consistent results, so I'm sharing it in case anyone else wants to use it.
I do most of my SDXL generation using Fooocus, so my prompts are mostly human readable descriptions of what you're seeing in the image. That's also why the generation info on the sample images is lacking. Most of my realistic images are generated using JuggernautXL, and I use DynavisionXL for cartoony stuff, but play around with other models and see what you come up with... that's what we're here for, right?
Usage:
I've gotten the best results with this while using a weight of 0.9-1.0 when used alone, or a weight of between 0.7-0.9 when in combination with some other LoRAs. This is a photorealistic LoRA but I genuinely get the best results using it with a more cartoony, 3d art style, which is what I wanted it for. I guess that helps cover up some of the oddities that pop up in generations.
Notes:
This model was trained mostly from Adobe/Dreamstime stock images, and not her Insta or OF content, so while it's capable of doing bikinis and showing skin, it wasn't trained on it and probably won't give good results if you try to do NSFW stuff with it without a lot of coaxing. It was trained with a solid variety of close-up and medium close-up portraits as well as longer full body shots in a variety of poses, using camera angle descriptions pulled from the following image, so you may get better results using this as a reference:
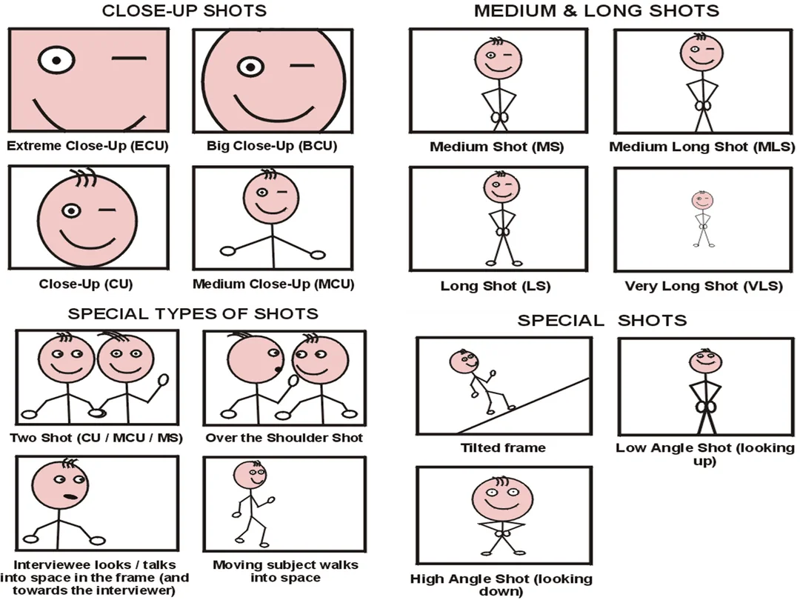
If you like the model, have some tips or tricks on how I could improve it, or just want to talk shop, please leave a comment. Ratings are appreciated, no matter what they are. And if you use the model and make something cool that you'd like to share, I'd love to see it! Enjoy!
Images Generated With This Model

Create Your Own AI Model

Create Your Own AI Model





Similar Models


Create Your Own AI Model


![Gamer Azura [RatoPombo] (Elder Scrolls) Character Lora](https://go_service.aieasypic.com/?url=https%3A%2F%2Fimage.civitai.com%2FxG1nkqKTMzGDvpLrqFT7WA%2Ffdd09fd5-1a8d-460b-b86b-c55cbd00d013%2Fwidth%3D450%2F2111502.jpeg&type=webp&width=500&quality=60&civitai=true)





