



Quick Generate
Model Description by Creator
FOREWORD
low rank adapters are not what they appear. when we make a parameter efficient fine tuning adapter for a stable diffusion model, we are tasking the image synthesis program to solve a complicated optimization problem which generates an entirely new program.
the process of selecting optimization problems does not yet have useful, specific, or strict rules which make it easy for us to choose the training settings or training data to produce image generation adapters (stable diffusion LoRAs) which do precisely what we want.
I hope to make navigating this problem a little bit easier.
ROTATE-SWORD
Training data preparation:

Literally draw something. Anything. It's all cool. The kind of texture you use will influence the behavior of your output adapter model, so using a paint-like texture instead of a crayon-like texture might better reflect your tastes and creative values.
The only important limit is to make sure that you color in whatever you draw, and use different colors to represent differences in depth, reflectivity, and patterns on the texture.
Mirror your image, rotate it in each of the 4 cardinal directions, and each of the 4 diagonal directions for a 16x multiplication of your training data.
Use a machine vision labeling tool for your training data. I do not recommend hand-labeling image caption training data unless you are a specialist in machine vision, and I can barely fine tune a text classifier.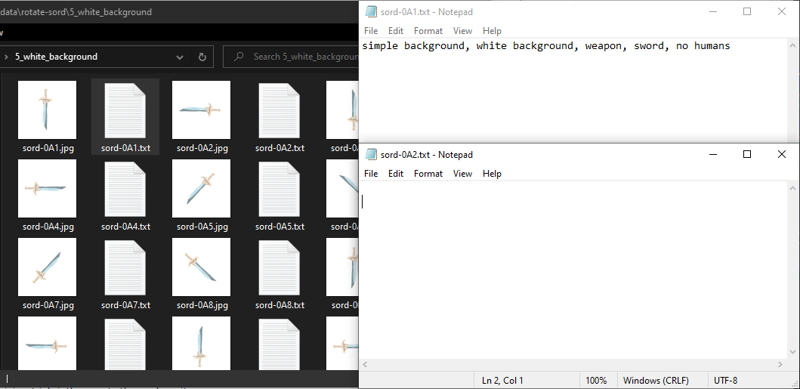
Check your training data to make sure that tags which reflect the object and background are propagated onto every single individual image. In my training set, I noticed that most of my images were missing most of the tags that they should have shared!
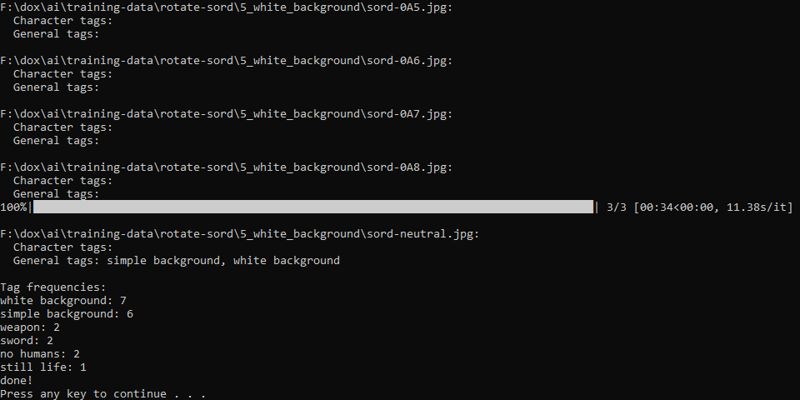
This is easily corrected by copying and pasting the valid tags a few times. If you are a more computer-prone person, I am certain you can find a way to use shell scripting to make that faster or simpler.
Training:
I used a network_dim of 64, a network alpha of 64. a learning rate of 5e-05 (in every field), an internal resolution of 768x768 (works even on 8gb gpus if you lower training batchsize!), ++a min_snr_gamma of 5.0,++ and a multires noise discount of 0.13. I used 5 'dataset repeats' and 12 epochs for my first training run. In your training, the total of (repeats*epochs) should be around 50-70. I would recommend no repeats and targeting 60 epochs so it is easier to see your adapter model changing in response to training.
training settings marked with a ++ are probably placebos and at least frivolous. they probably do not need to be imitated for good training results.
Make sure to save a checkpoint and sample an image at every single training epoch! 
The output model(s):
did i mention this training process took like 18 minutes without optimizing any training parameters, and hugely overshooting a converged output adapter model?
don't hesitate to train single-object single-texture loras on every single model you can find. train SD1.5. train SD2.0. try all of your favorite photorealistic and anime dreambooths!
as long as you're giving the training process a simple, straightforward optimization goal, through a constrained, specific dataset, all of the stable diffusion models will learn something interesting from your dataset.
Attached are rotate-sword loras using this exact training dataset and methodology using stable diffusion 1.5, NAI-leak, counterfeit-3, and my personal block-weight-merged model (like counterfeit, but with fewer purple splotches).
I recommend using the lora-ctl addon for automatic1111's webui with loras trained in this fashion. It is unlikely you want for your adapter model to generate endless white expanses or abstract backgrounds as your specific aesthetic goal. A lora-ctl alpha curve of <lora:loraname:1:[email protected],[email protected],[email protected]>will moderate behavior of that kind very nicely.















