



Quick Generate

Create Your Own AI Model
Model Description by Creator
Originally Posted to Hugging Face and shared here with permission from Stability AI.
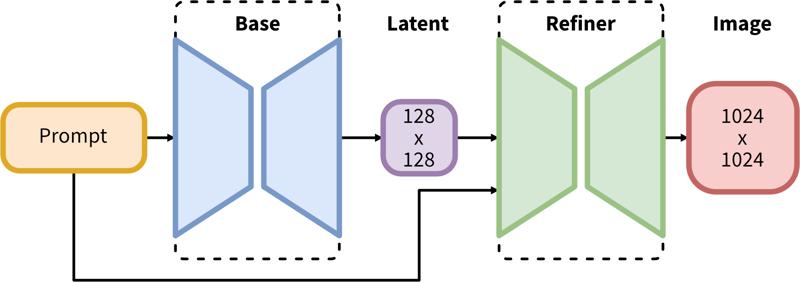
SDXL consists of a two-step pipeline for latent diffusion: First, we use a base model to generate latents of the desired output size. In the second step, we use a specialized high-resolution model and apply a technique called SDEdit (https://arxiv.org/abs/2108.01073, also known as "img2img") to the latents generated in the first step, using the same prompt.
Model Description
Developed by: Stability AI
Model type: Diffusion-based text-to-image generative model
Model Description: This is a model that can be used to generate and modify images based on text prompts. It is a Latent Diffusion Model that uses two fixed, pretrained text encoders (OpenCLIP-ViT/G and CLIP-ViT/L).
Resources for more information: GitHub Repository.
Model Sources
Repository: https://github.com/Stability-AI/generative-models
Demo [optional]: https://clipdrop.co/stable-diffusion
Uses
Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
Generation of artworks and use in design and other artistic processes.
Applications in educational or creative tools.
Research on generative models.
Safe deployment of models which have the potential to generate harmful content.
Probing and understanding the limitations and biases of generative models.
Excluded uses are described below.
Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
Limitations and Bias
Limitations
The model does not achieve perfect photorealism
The model cannot render legible text
The model struggles with more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
Faces and people in general may not be generated properly.
The autoencoding part of the model is lossy.
Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
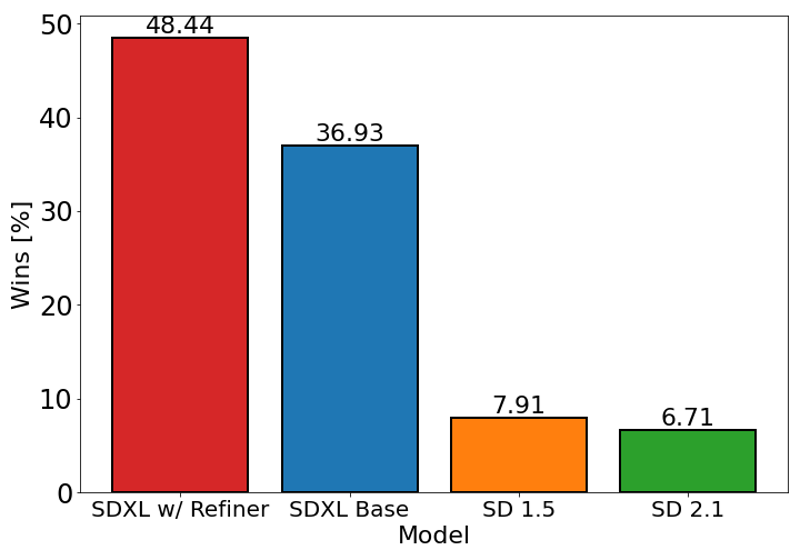
The chart above evaluates user preference for SDXL (with and without refinement) over Stable Diffusion 1.5 and 2.1. The SDXL base model performs significantly better than the previous variants, and the model combined with the refinement module achieves the best overall performance.
Images Generated With This Model

Create Your Own AI Model
Create Your Own AI Model





Similar Models
Create Your Own AI Model









