



Quick Generate
Model Description by Creator
Changelog:
beta: Removed DPO from merge. Model merged with FreeU and Self-Attention Guidance and different weights per model. Less saturation than previous version. More creative/artistic results with simple prompting.
alpha3: improvements with better coherence, better sharpness, better anatomy
alpha2: removes models with conflicting licenses; renaming for better organization
What to expect
This model can generate photorealistic images of people with decent anatomy. It can also do good images of cities and buildings, as well as logos and other cartoonish styles. Those are 3 qualities I'm trying to make this model excel at, but it can also do other styles and subjects.
Why I made this
I have a collection of around 40 favorite SDXL models and decided to merge my most used ones. I hoped to get a model able to satisfy my personal taste and demand for high quality scenarios, characters for my comics and logos/icons for my projects.
I merged 12 different models and 3 LoRAs. All 3 of which are listed on the suggested resources.
I believe there is still room for improvement on faces and hands on photography prompts. Future versions may include more models and different merge settings that I'm still experimenting. I don't have a fixed schedule for updates yet.
How can you use
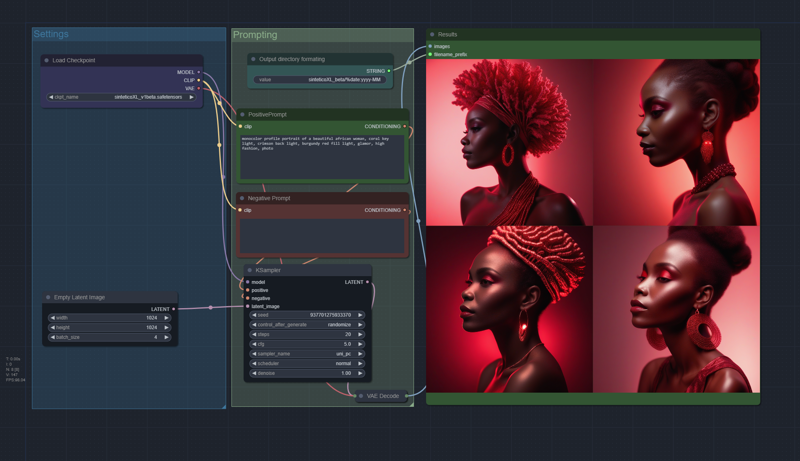
Complex prompting is not required, but can be helpful to guide towards your vision. A basic workflow is attached on the samples and may be loaded directly onto ComfyUI.
Commercial usage of generated images is allowed.
You are solely responsible for any content that you create using this model. In addition, your use of this model implies that you accept an agreement to not use it to produce harassing, harmful, illegal, or otherwise highly-objectionable imagery.
You may not resell this model or provide it as a service.
Roadmap:
stable: will use latest versions of all merged models.










![Noel Cornehl | ノエル·コルネール XL v1.0 [Alice in Cradle] -by AutoRunMech](https://go_service.aieasypic.com/?url=https%3A%2F%2Fimage.civitai.com%2FxG1nkqKTMzGDvpLrqFT7WA%2F34d0738d-2965-487d-bcfb-d1618288235c%2Fwidth%3D450%2F2496762.jpeg&type=webp&width=500&quality=60&civitai=true)




![Noel Cornehl | ノエル·コルネール XL v1.0 [Alice in Cradle] -by AutoRunMech](https://go_service.aieasypic.com/?url=https%3A%2F%2Fimage.civitai.com%2FxG1nkqKTMzGDvpLrqFT7WA%2F1cb9f5f4-ca60-4df2-831d-1f599b65c2d5%2Fwidth%3D450%2F968248.jpeg&type=webp&width=500&quality=60&civitai=true)