



Quick Generate

Create Your Own AI Model
Model Description by Creator
BIG SHOUT OUTS TO THE BLACK FOREST LABS, INC STAFF. Your hard work has paid off in a big way. Flux is a genuine achievement.
Run it on ComfyUI with seemingly any Flux workspace. I've included an image below that contains a convenient workflow.
This is both the fastest and most utilitarian method I found combining the clips and the dev model. It runs at a bit under 20 gigs vram instead of the full combination that took all of my vram and locked up my computer. Generations usually took under 20 seconds at 16 steps so it's faster than the base full version which was taking about 2 minutes each image. It successfully introduces text on newly stylized surfaces as well.
I merged the functional L clip from my SD3 consistency lora training with Pony Realism's L then jammed it into flux at about 80% flux Clip L. There's a full merge recipe below. It may or may not produce the same outcome, I can't remember the full combination. Everything I merged IS AVAILABLE ONLINE currently, so play with it instead of using mine and you'll have a lot more fun than just using the one I made. You may end up with a better one or even a way better one.
It introduces some very interesting stylish differences and doesn't actually butcher it too badly. It needs more steps than standard flux, and the VAE is baked in.
Prompt
Due to the pony merge, it seems to respond to score tags.
If using single prompt, I find this to be fairly effective. Experiment.
three people, count people in plain english for flux,
if using single prompt describe your prompt similar to this, individual sentences should be separated by commas but not periods
score_9, score_8_up, score_7_up,
1girl, 2girl, etc for danbooru and consistency anime,
other people tags and further description,
other danbooru tags to further define the description, use increased strength here
concluding description with something based on overlay rather than background like text or specific detailed overlaying stylesFlux HAS some danbooru tags already, but not too many. It has SOME. Mostly safebooru tags it seems.
Settings
Noticeably higher quality at 16+ steps.
euler
16 steps
The generations were on average less than 20 seconds.
standard config 1 for flux, i was experimenting with 7 and getting results when aiming for pony realism instead, around 5 seems to introduce a combination in a strange way
config rescale node hurts it but does something
sd3 scale destroys it completely, don't use it
The experiments showed; the higher the CLIP_L deviation from the original flux CLIP_L, the more disjointed and also the more different output images became. It was producing nearly identical context as Realism + Consistency at about 20% flux power, and the images looked completely disjointed and incorrect. The forms remained, so I toggled and tinkered until I found one that joined them in a cohesive and comprehensive way.
Recipe as I recall
PDXL Autism CLIP_L: 0.67
Consistency V1.1 LOHA: 0.33
-> Autism_Consistency_Clip_L was born
PDXL Autism_Consistency CLIP_L: 0.2
SD3 CLIP_L: 0.8
-> SD3_Consistency_Clip_L
LORA FINETUNE -> 0.8 LORA + SD3 MERGE CLIP_L
SD3_Consistency_Clip_L is born.
SD3_Consistency_Clip_L: 0.5
Pony_Realism_V2.1 CLIP_L: 0.5
-> STAGE_2_CONSISTENCY_REALISM_EXPERIMENT_SDXL_SD3
The original wasn't very interesting or potent with SD3 so I wrote it off.
Flux merge:
STAGE_2_CONSISTENCY_EXPERIMENT_SDXL_SD3: 0.2
Flux_Clip_L: 0.8
-> Current V1.0 Flux + ConsistencyPDXL + Flux Workflow
I've included a convenient one to mix both Flux and PDXL. Drag this image of the two girls from the gallery below, into comfy to use the Flux + PDXL workflow. It's not required, but it definitely provides an interesting avenue. You can unhook pdxl and run the top two prompts to simply use Flux.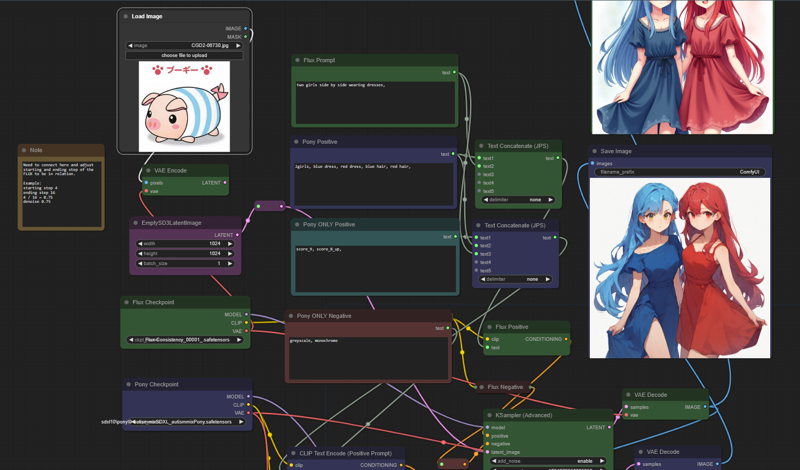
PDXL Autism Mix merged 0.33 strength Consistency LOHA Version 1.1
SD3 finetuned into SD3 LORA experiment v0.3 trained with SimpleTuner
Images Generated With This Model

Create Your Own AI Model

Create Your Own AI Model





Similar Models
Create Your Own AI Model








![Amateur Photography [Flux Dev]](https://go_service.aieasypic.com/?url=https%3A%2F%2Fimage.civitai.com%2FxG1nkqKTMzGDvpLrqFT7WA%2F97831020-f49b-45b5-ac08-4ac2cc318a14%2Fwidth%3D450%2F24973140.jpeg&type=webp&width=500&sigma=30&quality=60&civitai=true)

